Coding
CyberGIS
GeoAI
GIS
Open Source
Remote Sensing
Tutorial
From Raw Raster to AI-Ready: Processing Alaska’s IfSAR Images for Machine Learning on HPC
From Raw Raster to AI-Ready: Processing Alaska’s IfSAR Images for Machine Learning on HPC
calendar_todayMar 9, 2026
schedule5 min
read
In the remote, rugged terrain of Alaska, detailed mapping of waterways is essential for everything from conservation to flood management. This task, however, requires processing huge volumes of complex, high-resolution data. The Alaska IfSAR (Interferometric Synthetic Aperture Radar) dataset, developed by the U.S. Geological Survey (USGS), provides high-resolution raster images capturing Alaska’s unique elevation and hydrographic features at a 5-meter resolution. But raw data alone isn’t enough — before this data can drive machine learning (ML) models, it needs significant processing.
This article takes you through the intricate steps of transforming IfSAR data into a machine learning-ready format, demonstrating the use of High-Performance Computing (HPC) to manage these data-intensive processes.
Overview of the Alaska IfSAR Dataset
The IfSAR dataset is a goldmine for researchers. It includes topographic and hydrographic details of Alaska’s landscape, such as:
Topographic and Hydrological Indices: Indicators like D-Infinity Flow Direction and Topographic Position Index that reveal terrain shape and water flow.
Elevation Models: Digital Surface Models (DSM) with features like trees and buildings, and Digital Terrain Models (DTM) for bare ground.
Shallow Water Models: Simulations that predict water flow paths and drainage areas.
Terrain Openness & Curvature: Identifying natural features such as ridges and valleys.
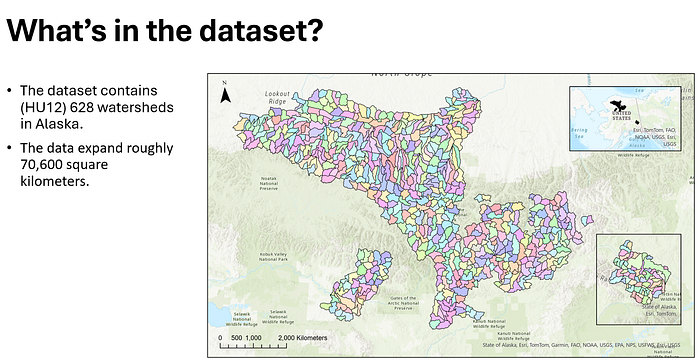
With over 628 watersheds and spanning nearly 70,600 square kilometers, the dataset provides a comprehensive representation of Alaska’s hydrography. However, processing and analyzing such large data volumes require efficient workflows and computational power.
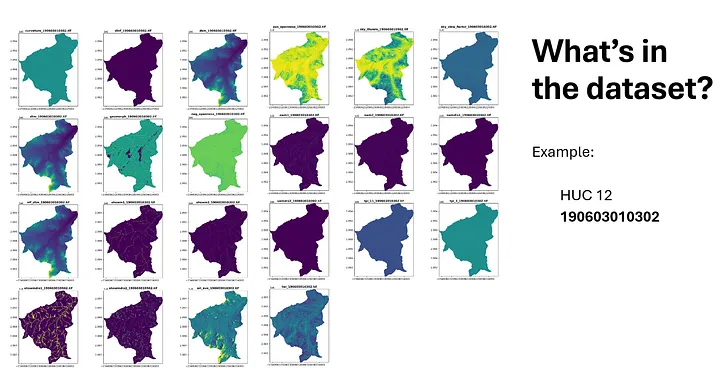
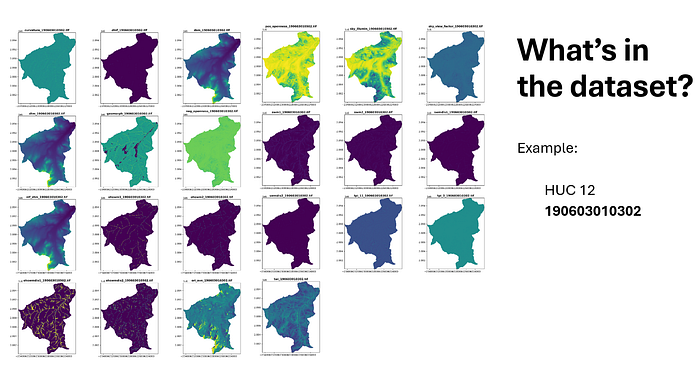
Overview of the by Alaska IfSAR Dataset: Covering approximately 70,600 square kilometers, this dataset includes 628 HUC 12 watersheds in Alaska. It provides detailed hydrographic and topographic data crucial for analyzing Alaska’s diverse and complex landscape.Dataset Example for HUC 12 Watershed 190603010302: A showcase of various raster layers, including curvature, flow direction, elevation models (DSM, DTM), topographic indices, and shallow water models. These layers provide comprehensive spatial information crucial for machine learning applications in hydrography.
The Challenges of Mapping Alaska’s Waterways
Creating maps that capture every twist and turn of Alaska’s waterways is no small feat. Some of the main challenges include:
Spatial Heterogeneity: Alaska’s landscape changes dramatically from one area to the next, making it hard for traditional models to generalize effectively.
Connectivity Complexity: Streams and rivers don’t always flow in a straight line, and they’re often interconnected in intricate ways that are difficult to capture.
Uncertain Flow Paths: Seasonal variations and natural barriers mean that water doesn’t always take a predictable path.
Computational Intensity: High-resolution data requires immense processing power, especially when running complex algorithms over vast areas.
These challenges call for smarter, adaptive approaches to streamline delineation — and that’s where machine learning comes into play.
Data Processing Pipeline: From Raw Data to Model-Ready
Turning IfSAR data into training data for ML models involves several key steps:
1. Patch Creation
Using Python’s Rasterio library, we read GeoTIFF files, the standard format for storing raster data, and break them down into smaller patches. Each patch represents a specific region of the watershed and includes critical features like elevation and water drainage patterns. The patching process involves:
Defining Patch Size: Ensuring patches are small enough for the model to process but large enough to capture relevant geographic details.
Sliding Window Creation: Moving a window across the image to generate patches while ensuring some overlap.
Validation: Ensuring that each patch contains a sufficient amount of waterway pixels so it contributes meaningfully to model training.
Each valid patch’s location is saved to a text file, enabling easy indexing during the training process.
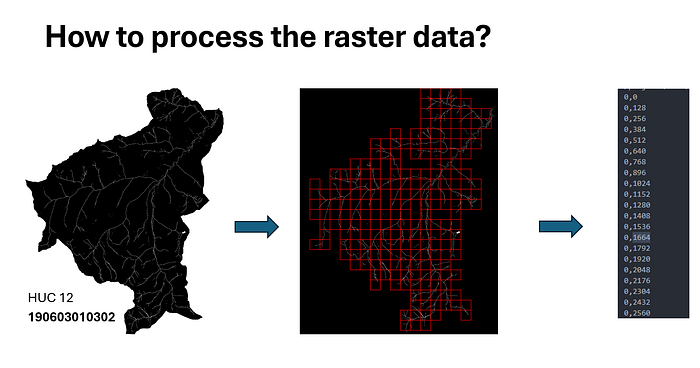
Patch Creation for Raster Data Processing: Starting with a HUC 12 watershed area (190603010302), the raster data is divided into grid patches using a sliding window. Valid patches are recorded with their coordinates for easy indexing, preparing them for downstream machine learning tasks.
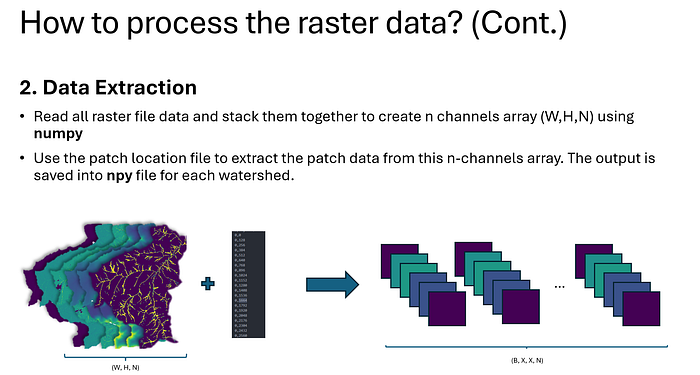
2. Data Extraction
Once patches are created, the next step is to extract specific layers or channels of interest. These layers are combined into a multi-channel array, typically structured as (Width, Height, Channels). For example:
Stacking Channels: Layers like DTM, DSM, and hydrological indices are stacked to provide the model with comprehensive information.
Organizing Patches: Using the saved patch locations, patches are indexed and saved into .npy files—an efficient format for fast data access during model training.
Data Extraction Process: Stacking raster files to create a multi-channel array (W, H, N) using numpy. Patch locations are used to extract data from this array, producing structured outputs in .npy format for each watershed, ready for machine learning model training.
This multi-channel format allows the ML model to analyze each patch from multiple perspectives, capturing not only the elevation but also the terrain’s structural features and water flow patterns.
Conclusion
Processing Alaska’s IfSAR data to make it machine-learning ready is a crucial step in unlocking insights about the state’s complex and beautiful waterways. By transforming raw raster images into structured, indexed data and leveraging the power of High-Performance Computing, researchers can build models that provide a clearer understanding of water flow, flood risk, and environmental patterns. This meticulous data preparation, combined with innovative machine learning techniques, paves the way for improved flood management, resource conservation, and sustainable development across Alaska and beyond.
For those interested in seeing this process in action, we have a live demonstration available on the CyberGISX platform. Visit https://go.illinois.edu/IfSAR-Demo to explore the Alaska IfSAR data processing workflow and learn how this data can drive meaningful insights through machine learning.
In the remote, rugged terrain of Alaska, detailed mapping of waterways is essential for everything from conservation to flood management. This task, however, requires processing huge volumes of complex, high-resolution data. The Alaska IfSAR (Interferometric Synthetic Aperture Radar) dataset, developed by the U.S. Geological Survey (USGS), provides high-resolution raster images capturing Alaska’s unique elevation and hydrographic features at a 5-meter resolution. But raw data alone isn’t enough — before this data can drive machine learning (ML) models, it needs significant processing.
This article takes you through the intricate steps of transforming IfSAR data into a machine learning-ready format, demonstrating the use of High-Performance Computing (HPC) to manage these data-intensive processes.
Overview of the Alaska IfSAR Dataset
The IfSAR dataset is a goldmine for researchers. It includes topographic and hydrographic details of Alaska’s landscape, such as:
Topographic and Hydrological Indices: Indicators like D-Infinity Flow Direction and Topographic Position Index that reveal terrain shape and water flow.
Elevation Models: Digital Surface Models (DSM) with features like trees and buildings, and Digital Terrain Models (DTM) for bare ground.
Shallow Water Models: Simulations that predict water flow paths and drainage areas.
Terrain Openness & Curvature: Identifying natural features such as ridges and valleys.
With over 628 watersheds and spanning nearly 70,600 square kilometers, the dataset provides a comprehensive representation of Alaska’s hydrography. However, processing and analyzing such large data volumes require efficient workflows and computational power.
Overview of the by Alaska IfSAR Dataset: Covering approximately 70,600 square kilometers, this dataset includes 628 HUC 12 watersheds in Alaska. It provides detailed hydrographic and topographic data crucial for analyzing Alaska’s diverse and complex landscape.Dataset Example for HUC 12 Watershed 190603010302: A showcase of various raster layers, including curvature, flow direction, elevation models (DSM, DTM), topographic indices, and shallow water models. These layers provide comprehensive spatial information crucial for machine learning applications in hydrography.
The Challenges of Mapping Alaska’s Waterways
Creating maps that capture every twist and turn of Alaska’s waterways is no small feat. Some of the main challenges include:
Spatial Heterogeneity: Alaska’s landscape changes dramatically from one area to the next, making it hard for traditional models to generalize effectively.
Connectivity Complexity: Streams and rivers don’t always flow in a straight line, and they’re often interconnected in intricate ways that are difficult to capture.
Uncertain Flow Paths: Seasonal variations and natural barriers mean that water doesn’t always take a predictable path.
Computational Intensity: High-resolution data requires immense processing power, especially when running complex algorithms over vast areas.
These challenges call for smarter, adaptive approaches to streamline delineation — and that’s where machine learning comes into play.
Data Processing Pipeline: From Raw Data to Model-Ready
Turning IfSAR data into training data for ML models involves several key steps:
1. Patch Creation
Using Python’s Rasterio library, we read GeoTIFF files, the standard format for storing raster data, and break them down into smaller patches. Each patch represents a specific region of the watershed and includes critical features like elevation and water drainage patterns. The patching process involves:
Defining Patch Size: Ensuring patches are small enough for the model to process but large enough to capture relevant geographic details.
Sliding Window Creation: Moving a window across the image to generate patches while ensuring some overlap.
Validation: Ensuring that each patch contains a sufficient amount of waterway pixels so it contributes meaningfully to model training.
Each valid patch’s location is saved to a text file, enabling easy indexing during the training process.
Patch Creation for Raster Data Processing: Starting with a HUC 12 watershed area (190603010302), the raster data is divided into grid patches using a sliding window. Valid patches are recorded with their coordinates for easy indexing, preparing them for downstream machine learning tasks.
2. Data Extraction
Once patches are created, the next step is to extract specific layers or channels of interest. These layers are combined into a multi-channel array, typically structured as (Width, Height, Channels). For example:
Stacking Channels: Layers like DTM, DSM, and hydrological indices are stacked to provide the model with comprehensive information.
Organizing Patches: Using the saved patch locations, patches are indexed and saved into .npy files—an efficient format for fast data access during model training.
Data Extraction Process: Stacking raster files to create a multi-channel array (W, H, N) using numpy. Patch locations are used to extract data from this array, producing structured outputs in .npy format for each watershed, ready for machine learning model training.
This multi-channel format allows the ML model to analyze each patch from multiple perspectives, capturing not only the elevation but also the terrain’s structural features and water flow patterns.
Conclusion
Processing Alaska’s IfSAR data to make it machine-learning ready is a crucial step in unlocking insights about the state’s complex and beautiful waterways. By transforming raw raster images into structured, indexed data and leveraging the power of High-Performance Computing, researchers can build models that provide a clearer understanding of water flow, flood risk, and environmental patterns. This meticulous data preparation, combined with innovative machine learning techniques, paves the way for improved flood management, resource conservation, and sustainable development across Alaska and beyond.
For those interested in seeing this process in action, we have a live demonstration available on the CyberGISX platform. Visit https://go.illinois.edu/IfSAR-Demo to explore the Alaska IfSAR data processing workflow and learn how this data can drive meaningful insights through machine learning.